关于 Kubernetes 中,拓扑感知你需要知道的一切
最近在搞在内部自研平台上做一些 NUMA 感知调度的工作,涉及到 kubernetes 节点资源拓扑的发现以及调度方面的内容。但是无奈才疏学浅,遇到问题查问题,一知半解的始终抓不到头绪,谨以此篇文章来梳理总结。
为啥需要感知拓扑
这里 kubernetes 官方说了:目前越来越多的系统利用 CPU 和硬件加速器,比如 GPU,DPU 来支持低延迟的任务以及高吞吐的并行计算任务。
但是好像又说的不清楚,其实本质原因是冯诺依曼架构带来的问题。还是那句老话,没有银弹,冯诺依曼架构将存储器和运算器分开,指令和数据均放在存储器,为现代计算的通用性奠定了基础。但是也埋下了隐患,那就是内存容量指数级提升后,CPU 和内存之前的数据传输成为了瓶颈。目前服务器中的设备基本都是通过 PCIe 总线进行高速连接,而不同的用途的服务器可能其总线布局也不相同,如下图所示(网上找到的,非本人所画),左图 GPU 驻留在不同的 PCIe 域上,GPU 内存之间的直接 P2P 复制是不可能的,从 GPU 0 的内存复制到 GPU 2 的内存需要首先通过 PCIe 复制到连接到 CPU 0 的内存,然后通过 QPI 链接传输到 CPU 1 并再次通过 PCIe 传输到 GPU 2。可以想象这个过程在延迟和带宽方面增加了大量的开销,而右图可以通过 GPU P2P 连接实现超高速通信。简单总结下,拓扑会影响设备间的通信,通信对业务造成稳定性以及效率,所以需要通过一些技术手段让业务感知拓扑。

PCIe Topo (figure 1)
拓扑类型
目前有哪些拓扑需要感知:
- GPU Topology Awareness
- NUMA Topology Awareness
GPU Topology Manager
业界目前有几种实现方案:
Volcano 目前未完全实现,智能云闭源只能通过一些分享的信息,管中窥豹。
Why
为什么需要 GPU 的拓扑感知,首先上个图,这张图来自 NVIDIA 官方,描述了现在主流的 GPU 显卡 V100 在服务器中的拓扑关系。

GPU Topo (figure 2)
每块 V100 GPU有6个 NVLink 通道,8块 GPU 间无法做到全连接,2块 GPU 间最多只能有2条 NVLink 连接。其中 GPU0 和 GPU3,GPU0 和 GPU4 之间有2条NVLink 连接,GPU0 和 GPU1 之间有一条 NVLink 连接,GPU0 和6之间没有 NVLink 连接,故 GPU0 与 GPU6 之间仍然需要通过 PCIe 进行通信。NVlink 连接的单向通信带宽为 25 GB/s,双向通信带宽为 50 GB/s,PCIe 连接的通信带宽为16 GB/s。所以在 GPU 训练过程中如果错误的分配了 GPU, 比如某训练任务 Pod 申请了两张卡 GPU0 与 GPU6,在跨 GPU 通信可能就成为了训练任务的瓶颈。
拓扑信息可以在节点执行命令查看:
|
|
How
这里就不一一解析,本身也没完整的实现来看,就以我自己的理解来梳理出一些大致思路。
第一步其实是感知,即通过 daemon 组件来进行 nvidia gpu 、网络拓扑、NVLink、PCIe 的信息。第二步则是调度器,定义策略。策略1:优先将同一个 NUMA node 下 NVLink 数最多的 GPU 调度到一个 Pod 上;策略2:优先将处于同一个 PCI switch 的 GPU 和网卡分配给同一个 Pod。大致整体思路如下:
- GPU-device-plugin 或者其他 daemon 进程,构造节点的 GPU 拓扑信息 CRD;
- Pod 定义 topo 策略,比如策略1或者策略2;
- 新定义调度器会根据 pod 调度的策略 fliter 、priority阶段过滤不满足策略节点,给满足策略节点打高分;
- 关于节点 gpu device 的发现更新交给 device-plugin 和 kubelet 来做, 参见文章。
目前 GPU 拓扑信息可以通过官方的 nvml (NVIDIA Management Library) 通过接口查询。
NUMA Topology Awareness
Why
谈到 NUMA 拓扑感知,一定要先解释 NUMA 是干啥呢,为啥要感知它呢?

NUMA Topo (figure 3)
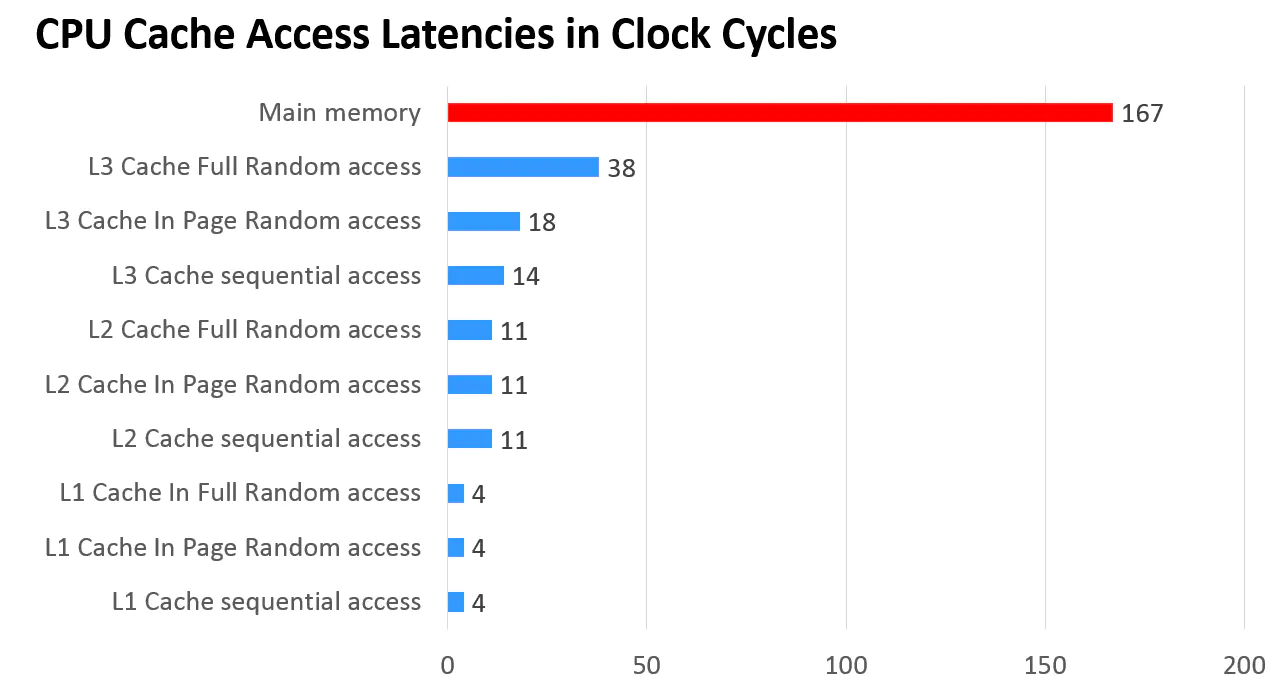
CPU Cache Latency (figure 4)
上面两幅图给你答案,现代 CPU 多采用 NUMA 架构, NUMA 全称 “Non-Uniform Memory Access” 即非一致性内存访问。为啥搞个非一致性,一致性不好吗?答案肯定是不好,因为如果使用 UMA 即一致性内存访问,随着北桥上的物理核心越来越多,CPU的频率也越来越高,总线带宽扛不住,访问同一块内存的冲突问题也会越来越严重。我们回到 NUMA架构,每个 NUMA node 上会有自己的物理CPU内核,以及每个 NUMA node 上核心之间之间也共享 L3 Cache。同时,内存也分布在每个NUMA node上的。某些开启了超线程的CPU,一个物理CPU内核在操作系统上会呈现两个逻辑的核。
回到业务侧,对于业务侧,如果程序都跑在同一个NUMA node上,可以更好地去共享一些L3 Cache,L3 Cache的访问速度会很快。如果L3 Cache没有命中,可以到内存中读取数据,访存速度会大大降低。
在容器大行其道的今天,由于 CPU 错误分配的问题尤为严重。因为现在节点出现了超卖,节点上有大量的容器在同时运行,如果同一个进行分配了不同的 NUMA 会发生什么问题:
- CPU 争抢带来频繁的上下文切换时间;
- 频繁的进程切换导致 CPU 高速缓存失败;
- 跨 NUMA 访存会带来更严重的性能瓶颈。
总结下:在现代 CPU 架构下,如果不感知 NUMA 拓扑关系,错误的进行 CPU 的分配,会导致性能问题,影响业务的 SLA。
How
上一章节阐述了为什么需要 NUMA 感知调度,那目前怎么感知 NUMA 拓扑呢,有什么现成的方案呢?这边我简单列下在 Kubernetes 生态的项目,各位看官如果有补充,可在评论区评论:
Kubernetes Topology Manager
拓扑管理器(Topology Manager) 是一个 kubelet 组件,旨在协调负责这些优化的一组组件。Topology Manager 其实是解决一个历史问题,CPU Manager 和 Device Manager 是独立工作的,互相不感知。 首先来看下 Kubernetes Topology Manager 的实现,这里我也不想造轮子了,可以参看阿里的同学总结的一篇好文。这里做一个总结:
- 找到不同资源的 topology hints 即拓扑信息, cpu 的选择标准是在满足资源申请的情况下,涉及的 NUMA 节点个数最少前提下涉及到 socket 个数最小的优先选择。 device manager 则在满足资源申请情况下,涉及 NUMA 节点最小优先选择。
- 不同 topology 类型的 hints 做 merge 操作,也就是 union,选出最优策略
如果选到还好,如果没选出来怎么办?kubernetes 提供了 kubelet 配置策略:
- best-effort: kubernetes 节点也会接纳这个 Pod,就是效果不达预期。
- restricted:节点会拒绝接纳这个 Pod,如果 Pod 遭到节点拒绝,其状态将变为 Terminated。
- single-NUMA-node:节点会拒绝接纳这个Pod,如果 Pod 遭到节点拒绝,其状态将变为Terminated。这里比 restricted 还多一个条件是选出来的 NUMA 节点个数需要是1个。
所以我们看到 Kubernetes Topology Manager 还是在以 NUMA 为中心来进行不同资源(NIC, GPU, CPU)来进行 complete fair 最短路径的选择。而且是在 pod 被调度到某个节点上后 kubelet 执行上述的过程,这样会带来几个问题:
- pod 有很大概率会 Terminated, 生产上不可用。
- 节点的 topology-manager-policy 配置不方便, kubelet 每次配置参数都需要重启,如果遇到特殊的版本可能会重启所有节点 pod,详见文章
所以我们会想到几个优化的方案:
- 让一个类似 kubelet 的 daemon 进程,可以发现 topo 关系,并向外暴露;
- 可以让拓扑感知放在 kube-scheduler 给 pod 分配 node 的时候就感知,而且可以指导调度;
- 提供声明式的灵活的 topology manager policy。
下面介绍的几个拓扑感知方案其实就是基于上面的 idea 应运而生的。
Crane NUMA 拓扑感知
首先看下 Crane NUMA 感知调度的架构图。
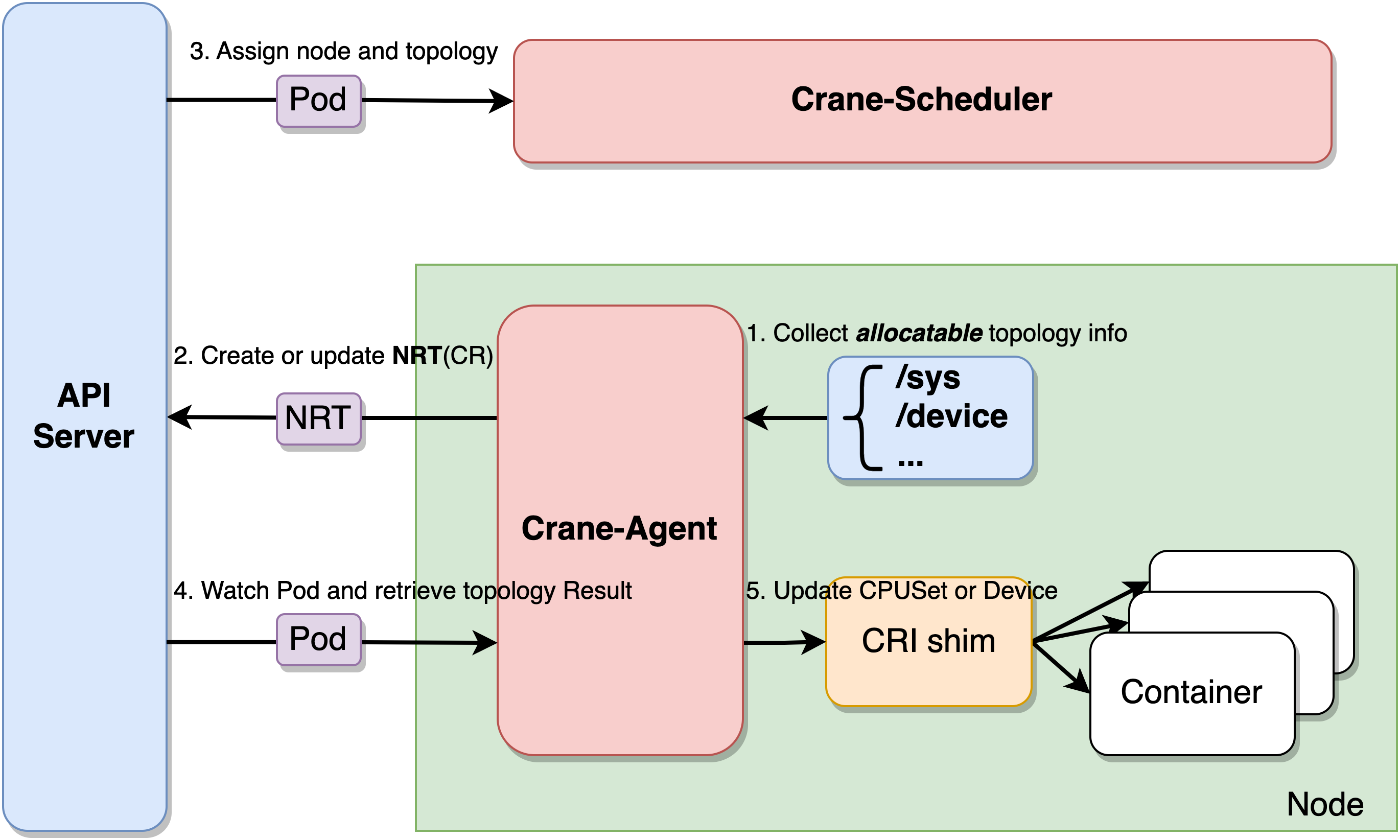
Crane NUMA Topology Aware (figure 5)
大致流程如下:
- Crane-Agent 从节点采集资源拓扑,包括NUMA、Socket、设备等信息,汇总到NodeResourceTopology这个自定义资源对象中。
- Crane-Scheduler在调度时会参考节点的NodeResourceTopology对象获取到节点详细的资源拓扑结构,在调度到节点的同时还会为Pod分配拓扑资源,并将结果写到Pod的annotations中。
- Crane-Agent在节点上Watch到Pod被调度后,从Pod的annotations中获取到拓扑分配结果,并按照用户给定的CPU绑定策略进行CPUSet的细粒度分配。
这里其实就已经解决上述 Kubernetes Topology Manager 的缺陷。不过我们发现策略怎么配置呢,这里提供两种策略配置方案
- 业务侧,在 pod 上打不同的标签来指定策略:
- none:该策略不进行特别的CPUSet分配,Pod会使用节点CPU共享池。
- exclusive:该策略对应kubelet的static策略,Pod会独占CPU核心,其他任何Pod都无法使用。
- NUMA:该策略会指定NUMA Node,Pod会使用该NUMA Node上的CPU共享池。
- immovable:该策略会将Pod固定在某些CPU核心上,但这些核心属于共享池,其他Pod仍可使用。
- 节点侧
- 目前默认是 cpu manager policy 是 static 即允许为节点上具有某些资源特征的 Pod 赋予增强的 CPU 亲和性和独占性; topology manager policy 是 SingleNUMANodePodLevel。
- 如果节点无
topology.crane.io/topology-awareness标签,则 topology manager policy 为 none
这里有个比较特别的功能,默认 kubelet 的 static 的 cpu manager 策略,只对 pod qos 为 guranteed 且资源申请为整数的 pod 生效,且分配指定的 cpu 其他进程无法占用。但是配合 crane-agent 和 Crane NUMA 感知调度后, 可以实现 pod 和 绑定核心的 pod 共享资源,可以在利用绑核更少的上下文切换和更高的缓存亲和性的优点的前提下,还能让其他 workload 部署共用,提升资源利用率。而且放松了 pod 的要求,只需要任意container的CPU limit大于或等于1且等于CPU request即可为该container设置绑核。实验下:
|
|
符合预期, 这里 cpuset 看官不了解可以参看 Linux Cgroup 入门教程:cpuset。
Koordinator Fine-grained cpu orchestration
Koordinator 和 Crane 在 NUMA 感知这块的架构是类似的,koordlet 替代 crane-agent, koord-scheduler 替代 crane-scheduler, 甚至描述节点 topo 的 CRD 都是一样的名字 NRT。这里梳理几个不同的点:
- Koordinator 支持的 cpu manager 的策略更多,除了 static 还支持申请完整物理核心的 full-pcpus-only 策略,以及需要多个 NUMA 满足分配情况下的均匀分配策略 distribute-cpus-across-NUMA。
- Koordinator 支持基于 NUMA 拓扑更多的调度策略, 比如 bin-packing 优先调慢一个节点或者分配到最空闲的节点。
- 此外 Koordinator 相对于 crane 在 PodQos 以及 CPU manager 上的粒度更细,这也是为啥叫 Fine-grained cpu orchestration 的原因吧,回头单独整一篇文章来详细解读下。
引用
这里站在巨人的肩膀上,再次感谢。
- https://kubernetes.io/zh-cn/
- https://github.com/volcano-sh/volcano/
- https://mp.weixin.qq.com/s/uje27_MHBh8fMzWATusVwQ
- https://www.infoq.cn/article/tdfgiikxh9bcgknywl6s
- https://github.com/NVIDIA/go-nvml
- https://gocrane.io/zh-cn/docs/
- https://koordinator.sh/docs/user-manuals
- https://www.likakuli.com/posts/kubernetes-kubelet-restart/
- https://zhuanlan.zhihu.com/p/121588317